基于图Transformer的多目标跟踪研究
2225 字
12 分钟

近年来,多目标跟踪(MOT)作为计算机视觉领域的一个重要研究方向,受到了广泛关注。传统的MOT方法(TBD范式)通常依赖于检测器和关联算法的结合,对于复杂场景,尤其是在复杂3D环境下的多目标跟踪,复杂的非线性运动的关联问题如果使用传统方法,有赖于人工设计的特征和启发式规则。同时,在这些场景中,基于Transformer的端到端的方法隐式处理关联过程,无法针对性的优化关联问题。而使用图结构来建模关联问题,能将复杂问题转化为一个图优化问题,通过深度学习的方法来显式优化关联过程,提升多目标跟踪的性能。
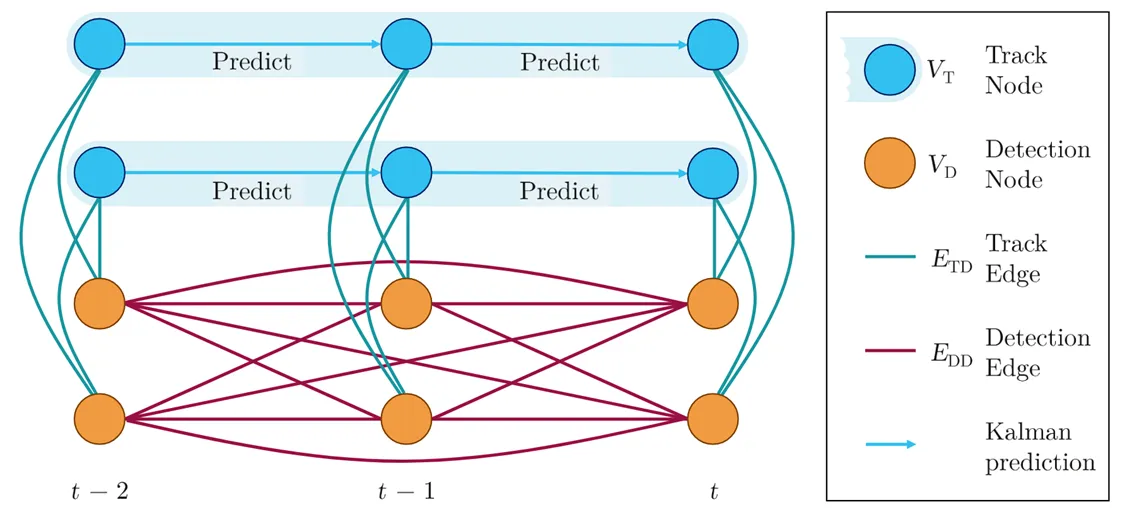
如图就是使用图结构建模关联过程的示意图。我们将检测和轨迹都抽象为图中的节点,节点之间的边表示检测和轨迹之间、检测和检测之间的关联关系。在这一图结构中,我们可以通过学习节点和边的特征来捕捉复杂的关联关系,从而提升多目标跟踪的性能。
但是,这个图结构仍然存在一些问题:
针对上述问题,3DMOTFormer使用基于图Transformer的方法,并改进了图结构和节点表示:
3DMOTFormer的图结构如图所示:
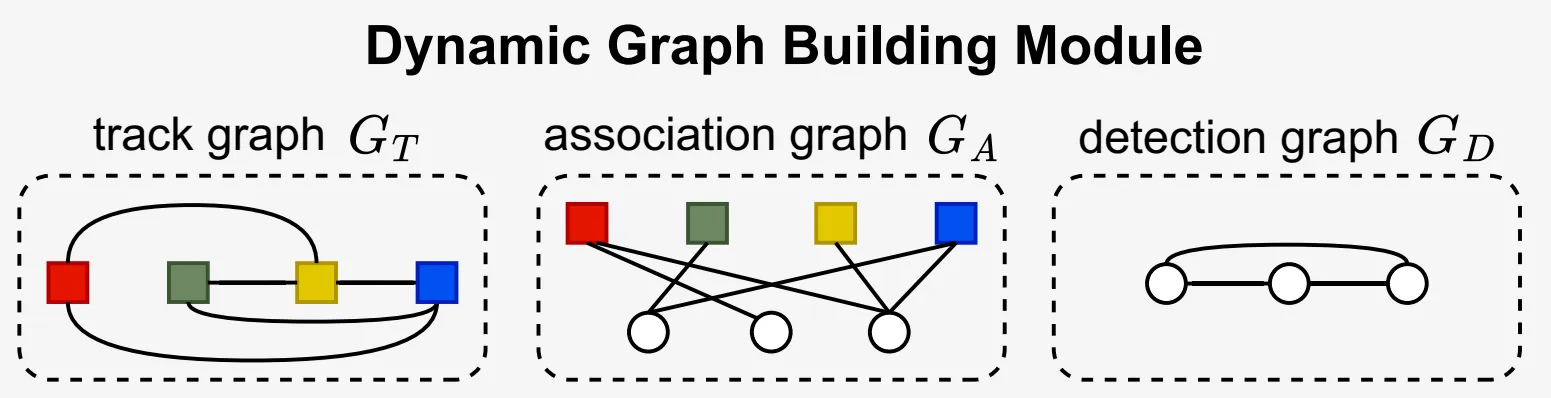
将整个关联问题建模为一个三个相互作用的子图:
其中检测和轨迹图的边隐式的表示节点之间的连接关系,而关联图的边则显式地表示检测和轨迹之间的关联关系。所有图的边都使用固定的阈值进行稀疏化处理,减少计算量。
3DMOTFormer中的图Transformer模块主要是从下面两种注意力机制进行设计:
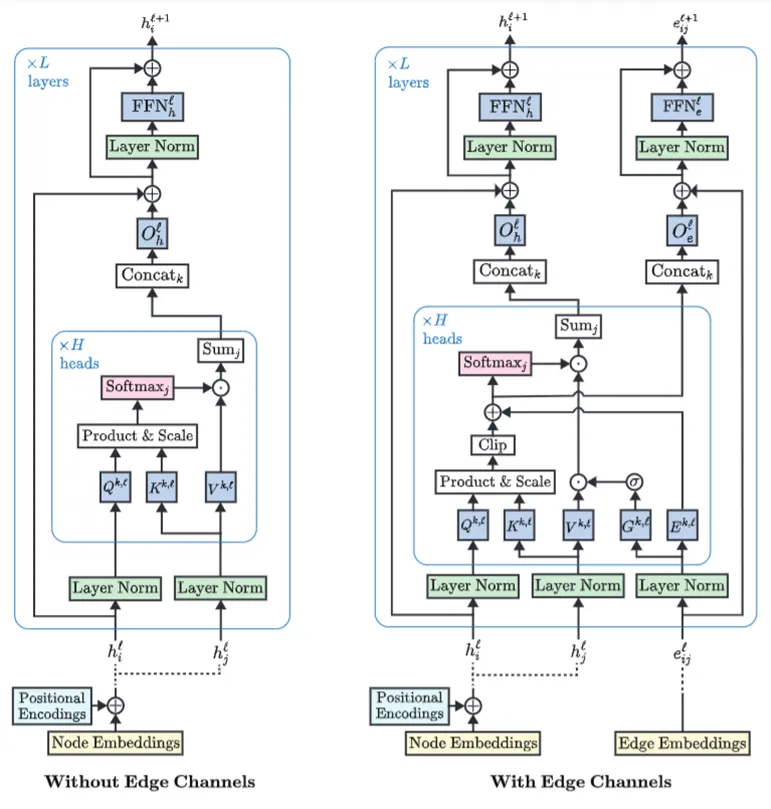
图Transformer模块由多个图注意力层堆叠而成。检测图与轨迹图仅利用边来定义节点间的邻接关系,以构建稀疏自注意力的计算范围;其边本身不携带可学习的特征表示,亦不在网络中显式更新。关联图作为轨迹与检测之间的二分图,其边不仅限定了匹配候选集,还被赋予显式的几何特征(如位置差、尺寸差、偏航角差等),并通过有边通道的图注意力机制进行多层特征更新。这种设计将轨迹和检测之间的关联关系显式地融入注意力计算过程,实现节点与关联边的联合建模、协同优化。
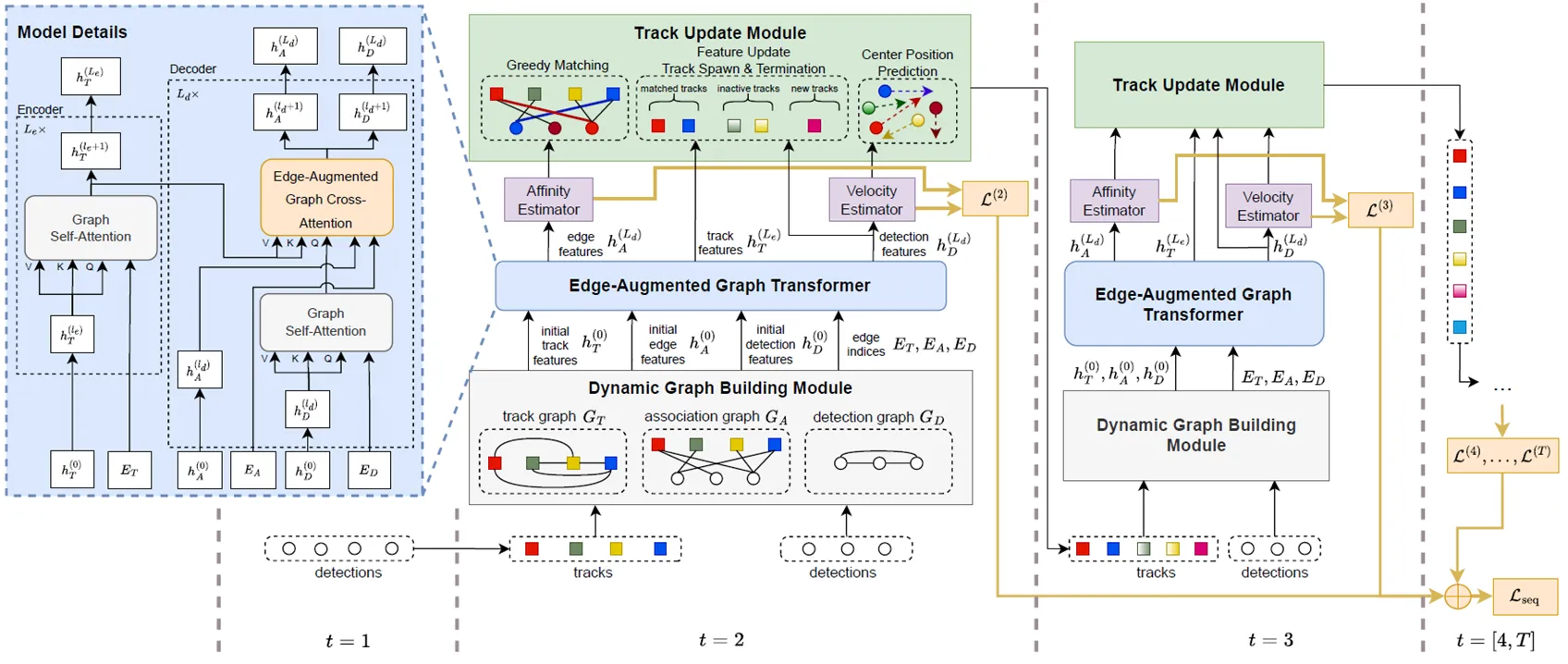
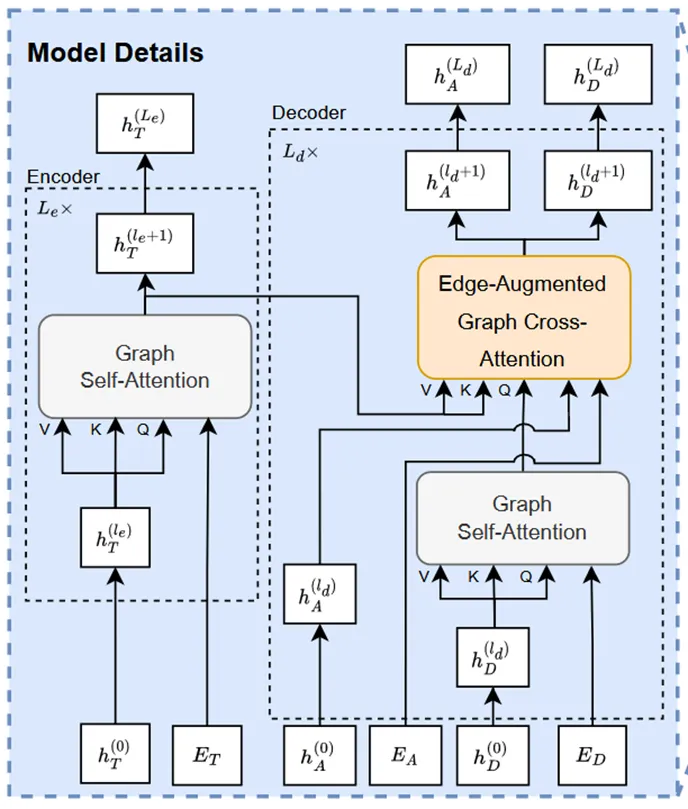
3DMOTFormer的整体架构如图所示。首先,输入当前帧的检测结果和上一帧的轨迹节点特征,构建检测图、轨迹图和关联图。然后,将这些图输入到多个图Transformer模块中进行特征更新。最后,通过一个二分类器对关联边进行分类,判断检测和轨迹之间的关联关系,从而实现多目标跟踪。
特别地,匹配过程使用最后一层的关联边特征,通过多层感知机得到检测和轨迹之间的匹配分数。使用贪心算法:从置信度高的检测开始,依次与轨迹进行匹配,直到所有检测或轨迹都被匹配完毕。
3DMOTFormer通过单阶段的方法处理了多目标跟踪中的关联问题,但是,其中节点特征中只有位置、尺寸等几何信息,缺乏外观信息,将这一模块融入到端到端的检测和跟踪框架中,可以利用检测器提取的丰富外观特征,提升跟踪性能。
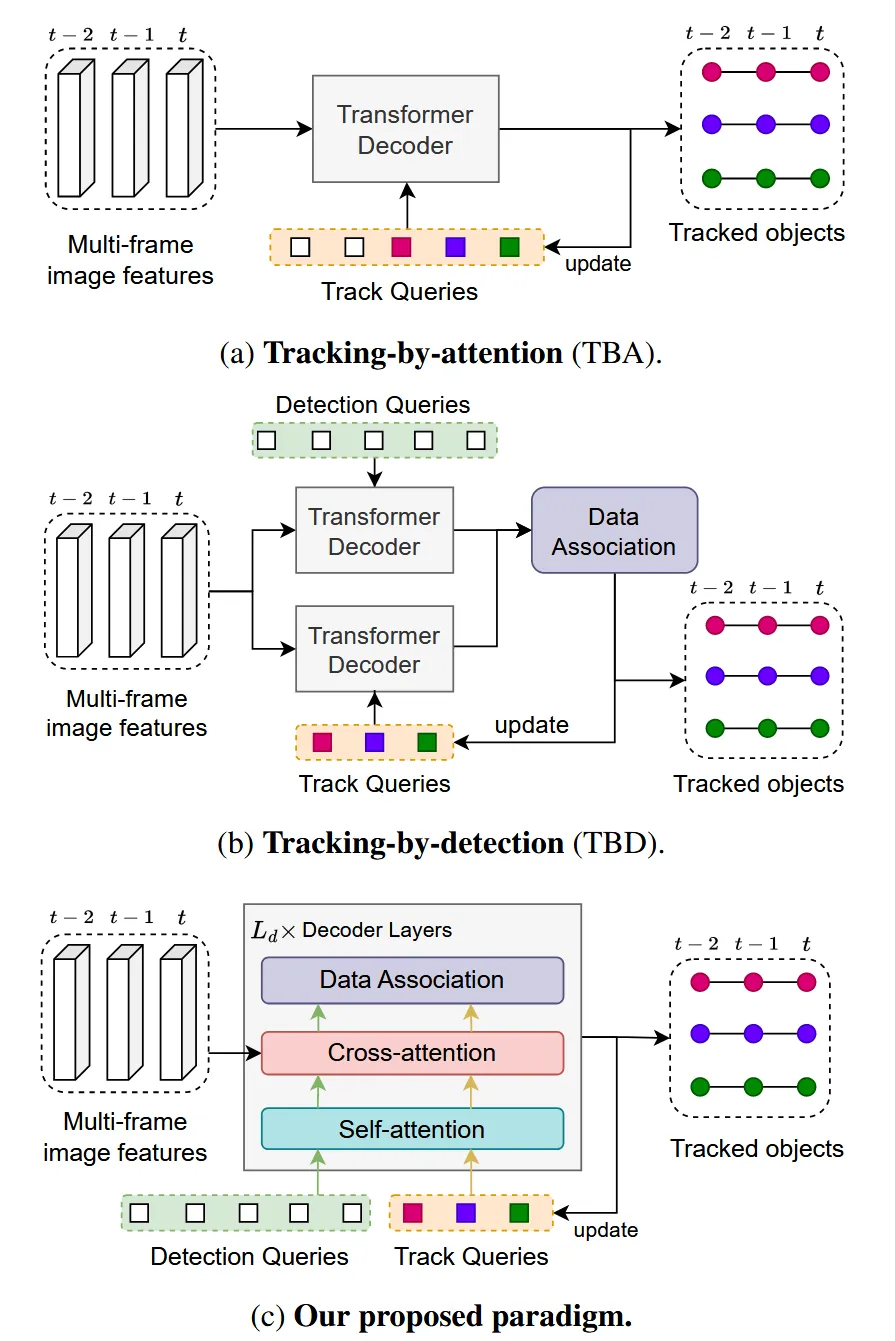
传统的基于Transformer多目标跟踪方法通常使用固定数量的轨迹查询,通过交叉注意力与图像特征交互,生成轨迹输出;匹配过程被隐式决定,无法直接访问或优化关联得分。而ADA-Track引入了专门的数据关联模块,匹配过程被明确建模为一个子任务,可通过调整损失函数进行优化。
ADA-Track的核心思想是交替检测和关联。其解码器层由两个交替的模块组成:检测模块和关联模块。检测模块负责生成当前帧的检测结果,关联模块则负责将当前帧的检测结果与上一帧的轨迹进行关联,实现实现检测与关联的协同优化。
模块说明检测模块
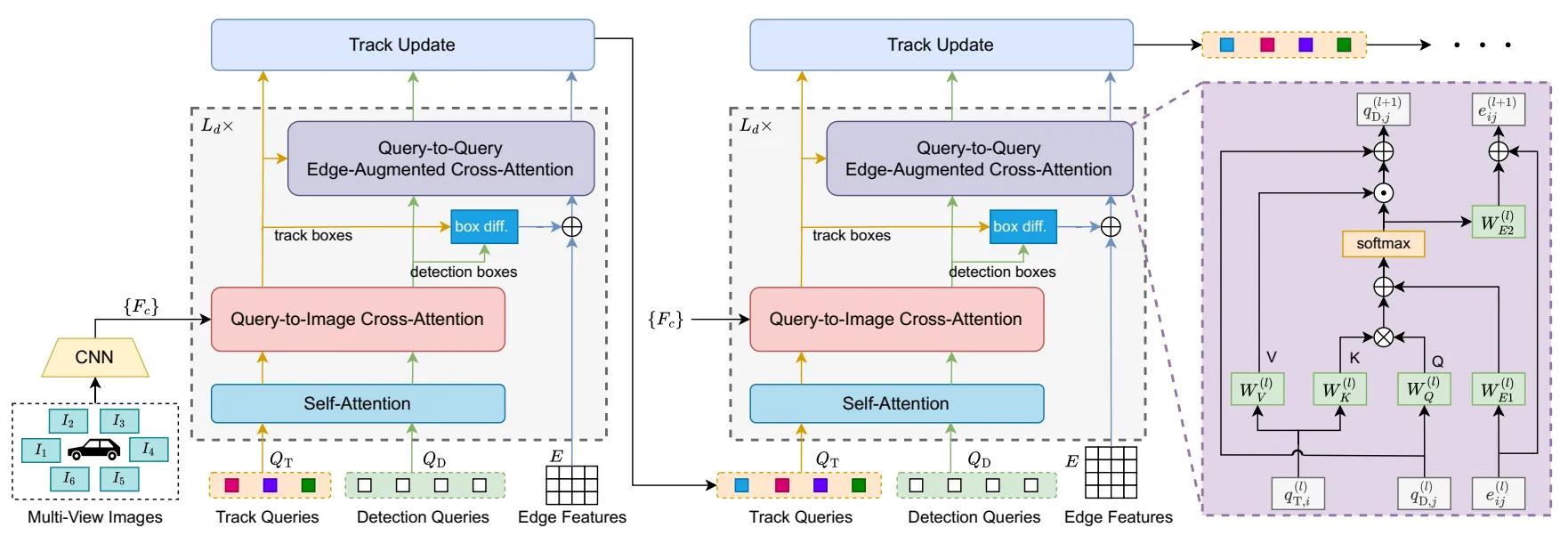
- 在自注意力层,通过将检测查询和轨迹查询拼接在一起做自注意力操作,使得检测查询能够将轨迹查询作为先验信息,在对图像进行解码时更好地定位目标,轨迹查询也能利用检测查询的信息,从而提升检测性能。
- 在查询与图像的交叉注意力层,将轨迹查询和检测查询一起作为查询,图像特征作为键和值进行交叉注意力操作,得到检测框和轨迹框的特征表示。
关联模块
- 基于3DMOTFormer 中的边增强的图注意力机制 (该模块本质为动态二分图Transformer)
- 但不同层之间的查询位置不同,为了确保不同层之间具有相同的图结构,此处使用了全连接图而非稀疏图
损失函数设计上,ADA-Track结合了检测损失和关联损失。检测损失用于优化检测模块的性能,而关联损失则用于优化关联模块的匹配效果。通过联合优化这两个损失函数,ADA-Track能够实现更准确的多目标跟踪。
其中, 和 分别表示第t帧的检测分类损失和回归损失, 和 分别表示第t帧的轨迹分类损失和回归损失, 表示第t帧的关联损失,、 和 是相应的权重系数。
